

一家文档智能公司的长期主义

故事的开始
并不轻松的决定
好技术的标准
解决疑难杂症
尊重用户
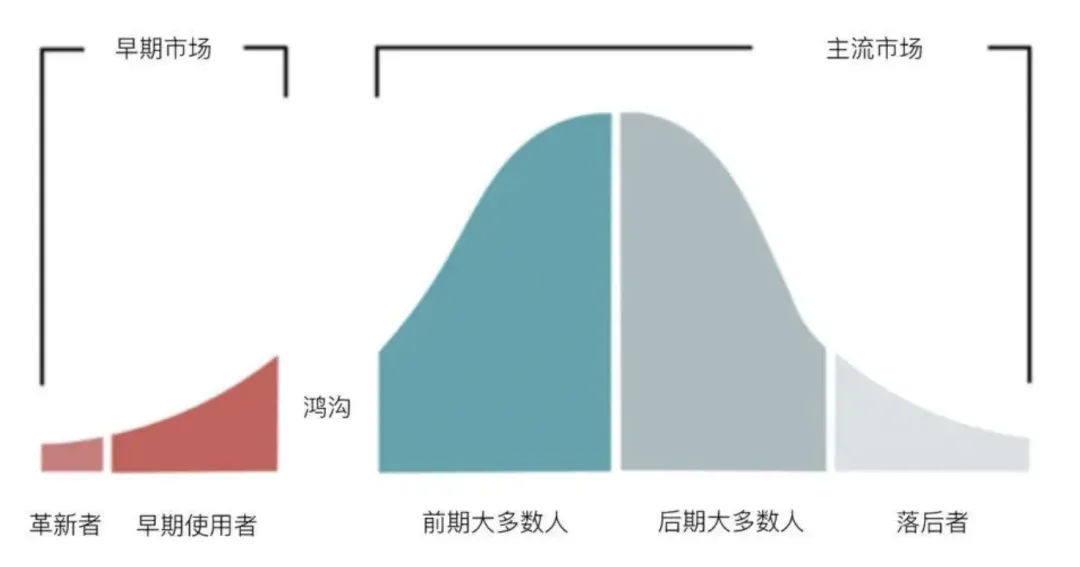
国内 3 款:Y品牌,B品牌,W品牌
国外 1 款:N品牌
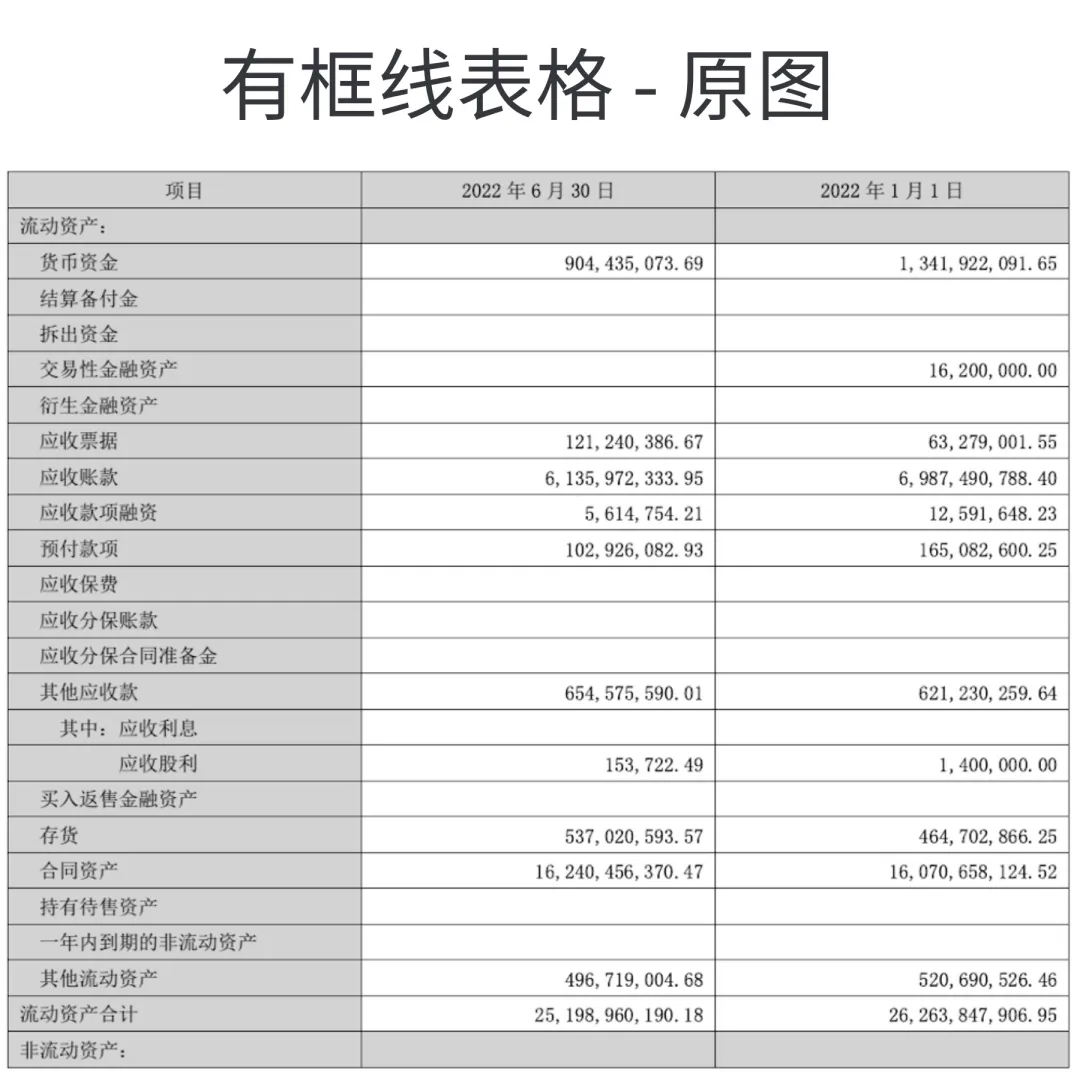
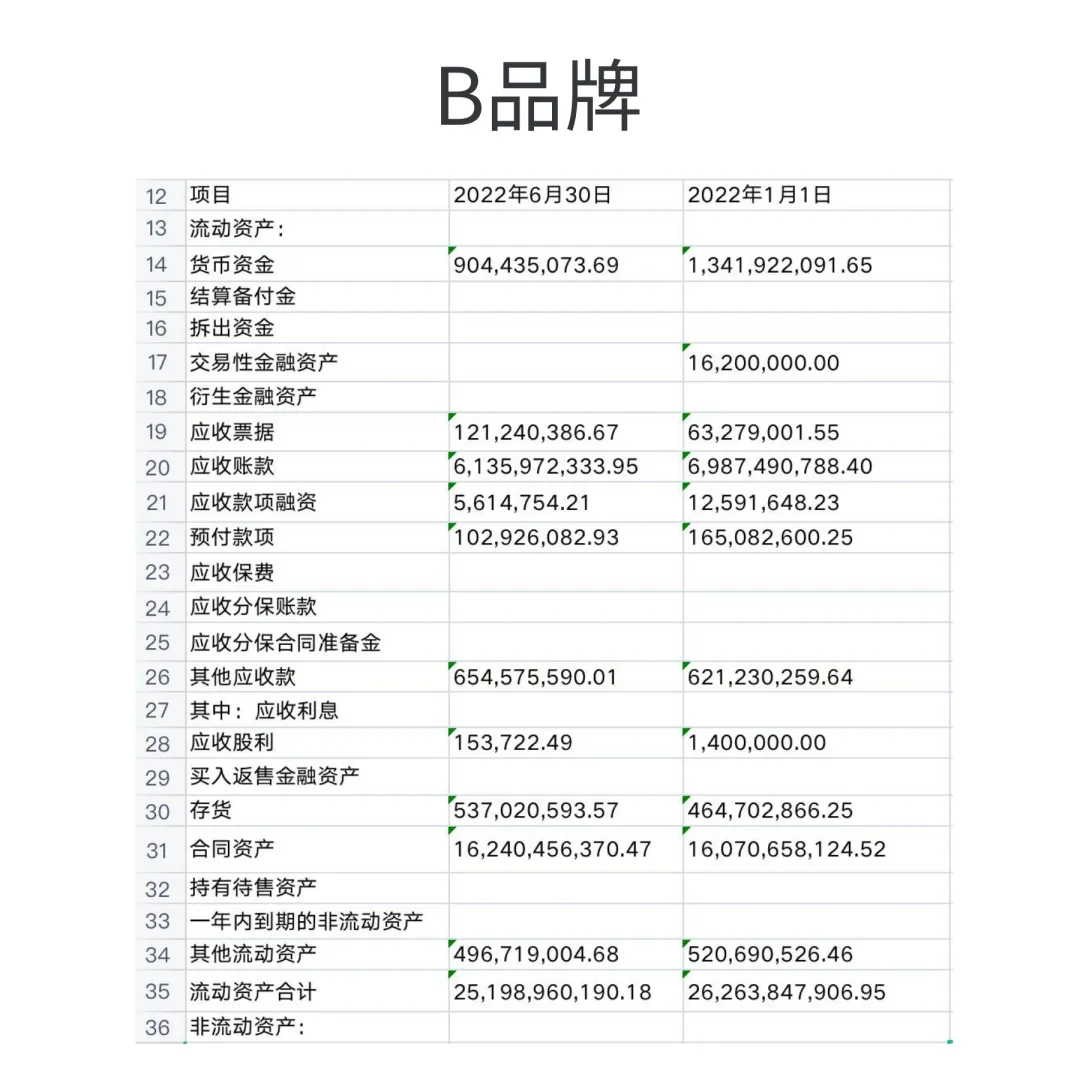
有框线表格:各款产品均表现良好
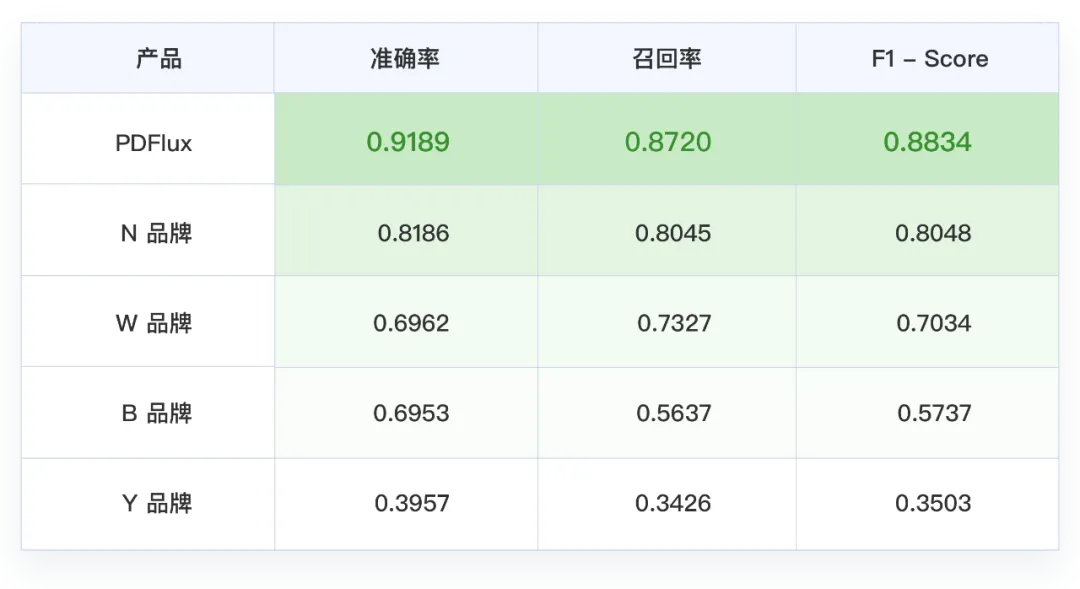
无框线表格:PDFlux,N品牌识别更准
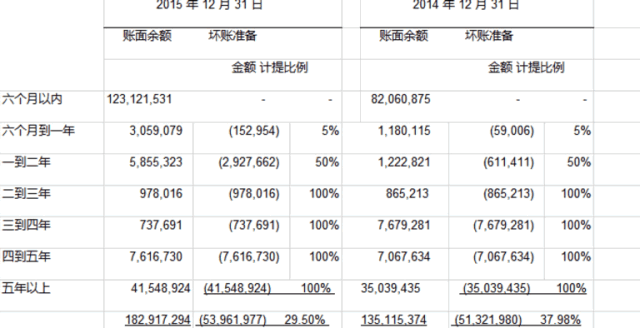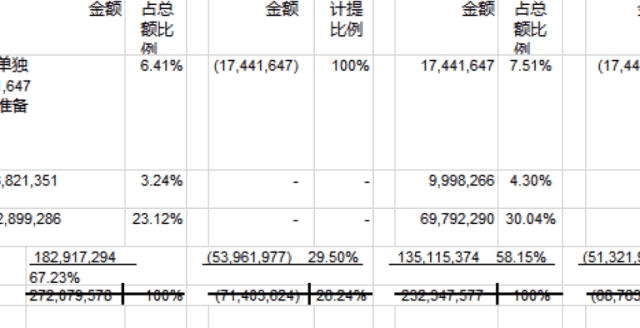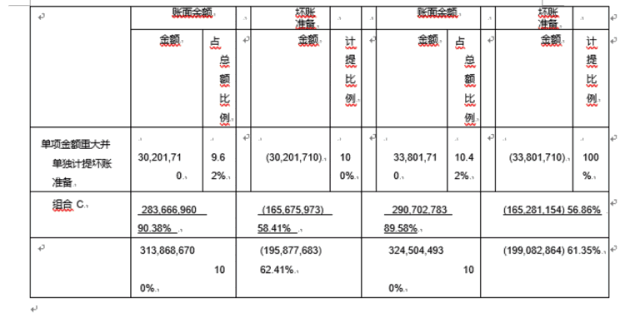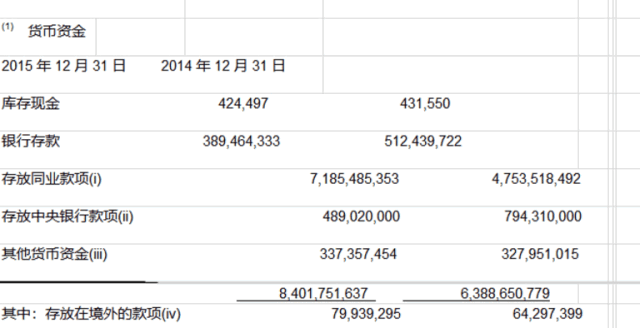
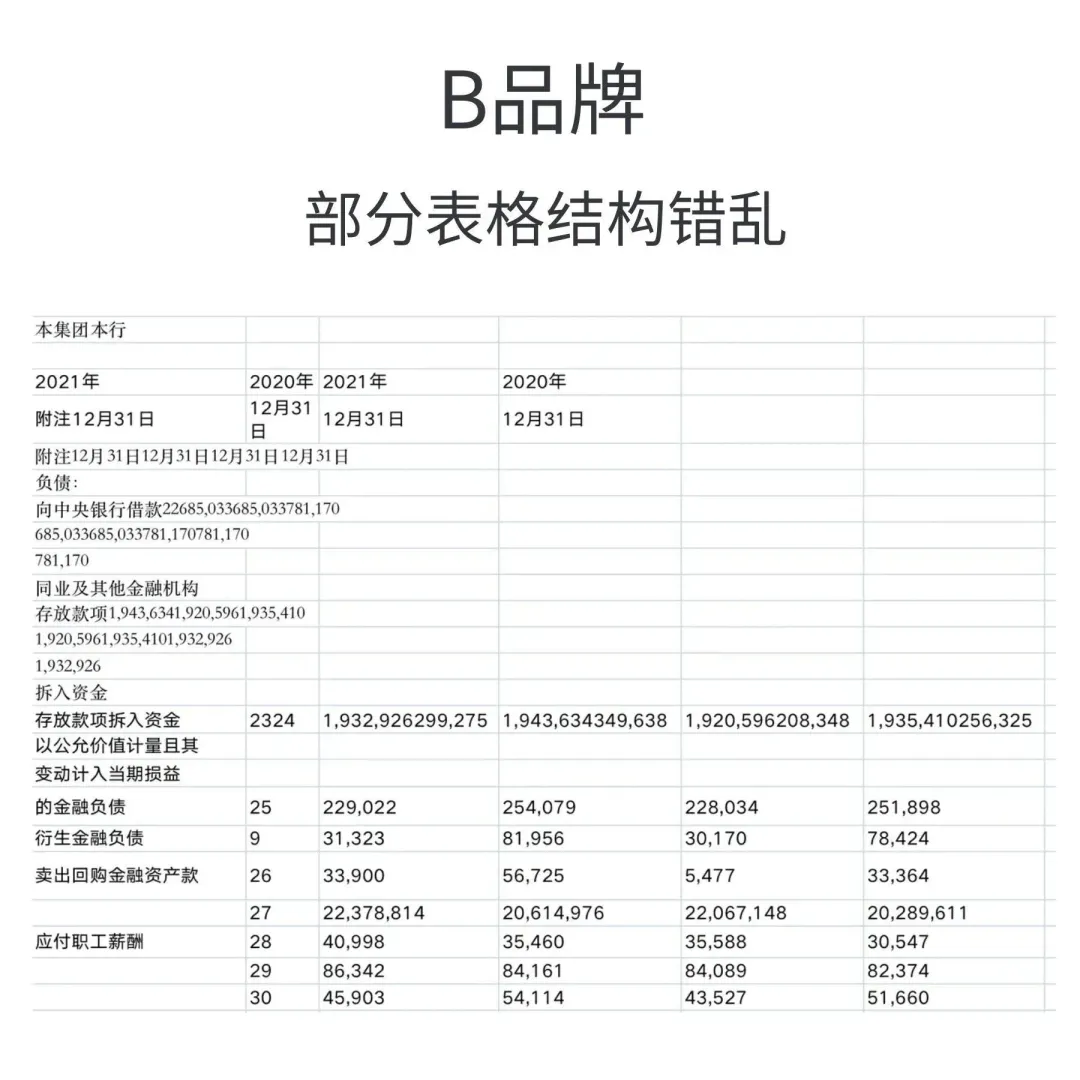
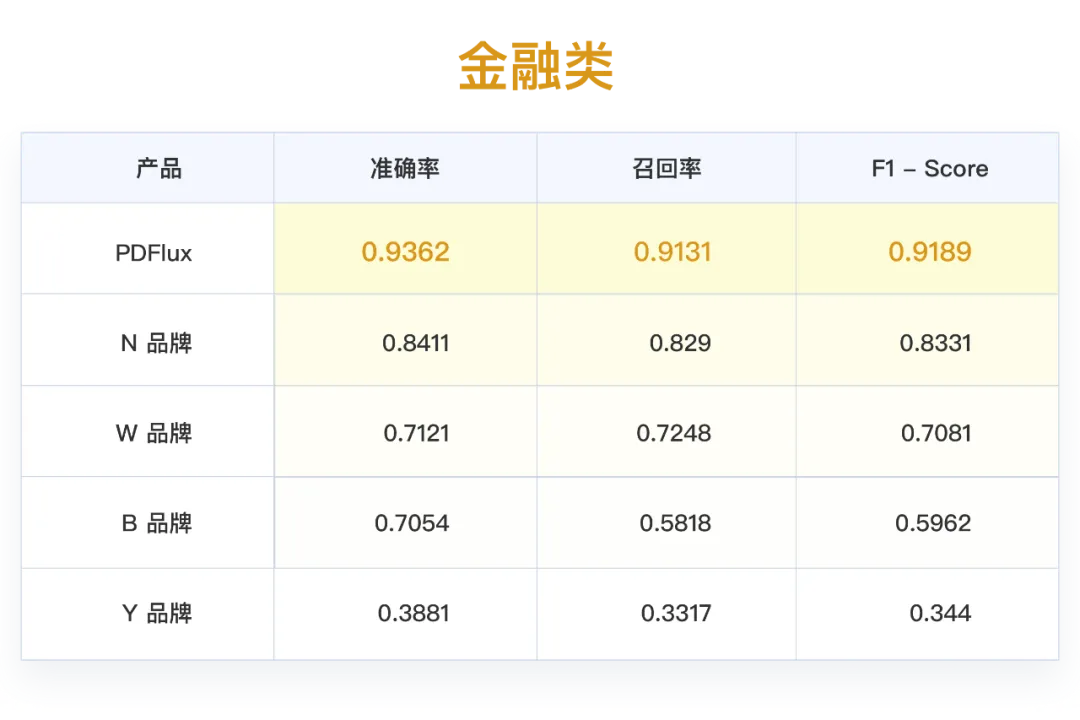
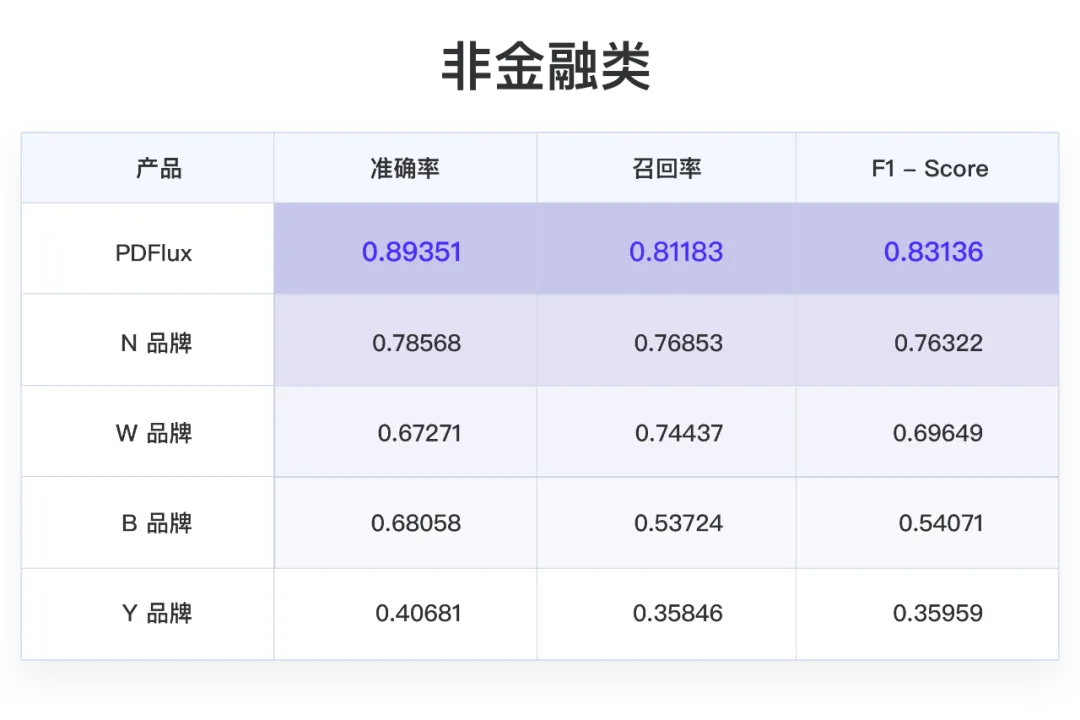
金融类表格:PDFlux,N品牌数据更准
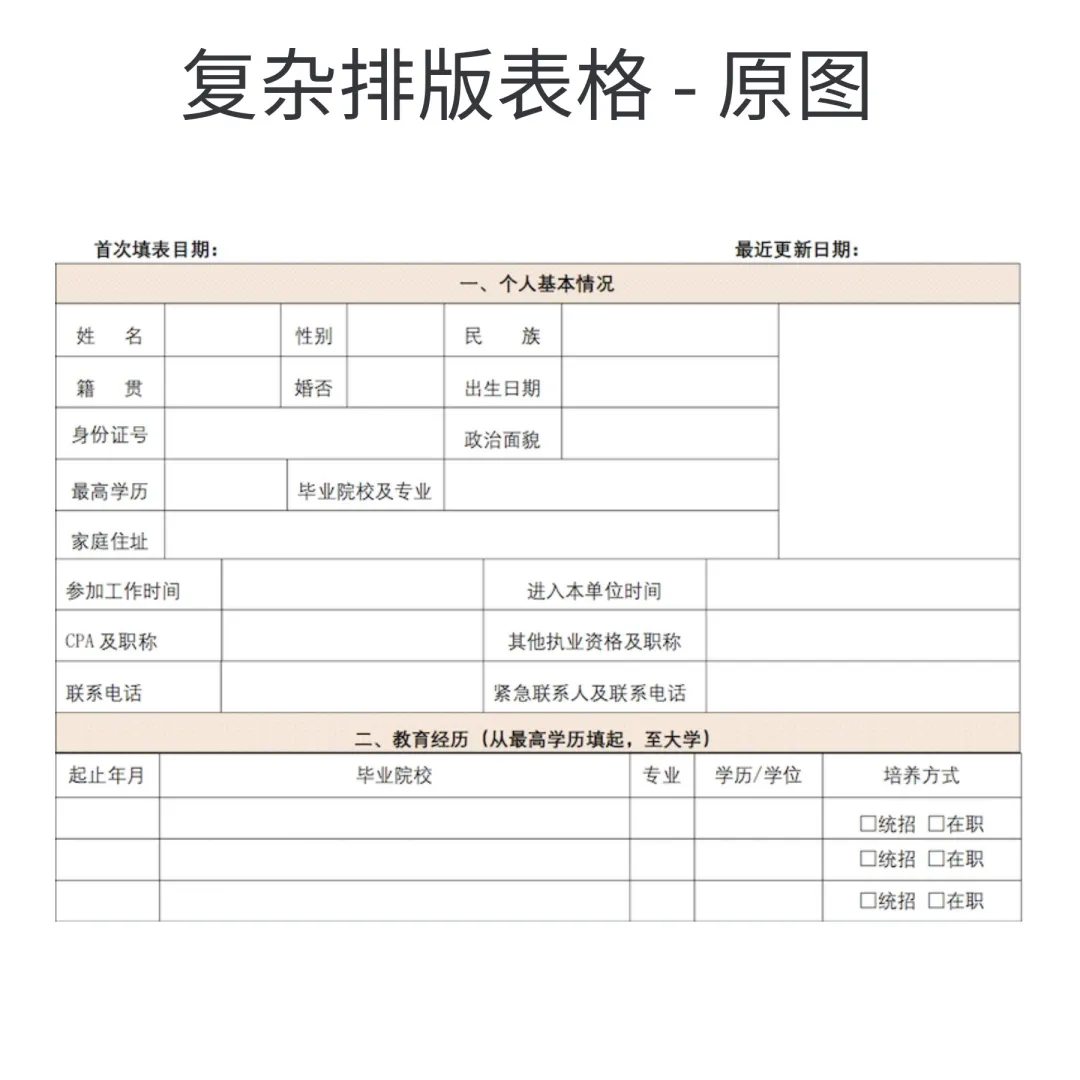
复杂排版:PDFlux,W品牌识别更好
照片扫描件:PDFlux,N品牌效果更好
印章干扰:PDFlux 不仅可以避免印章干扰识别表格,还能提取印文




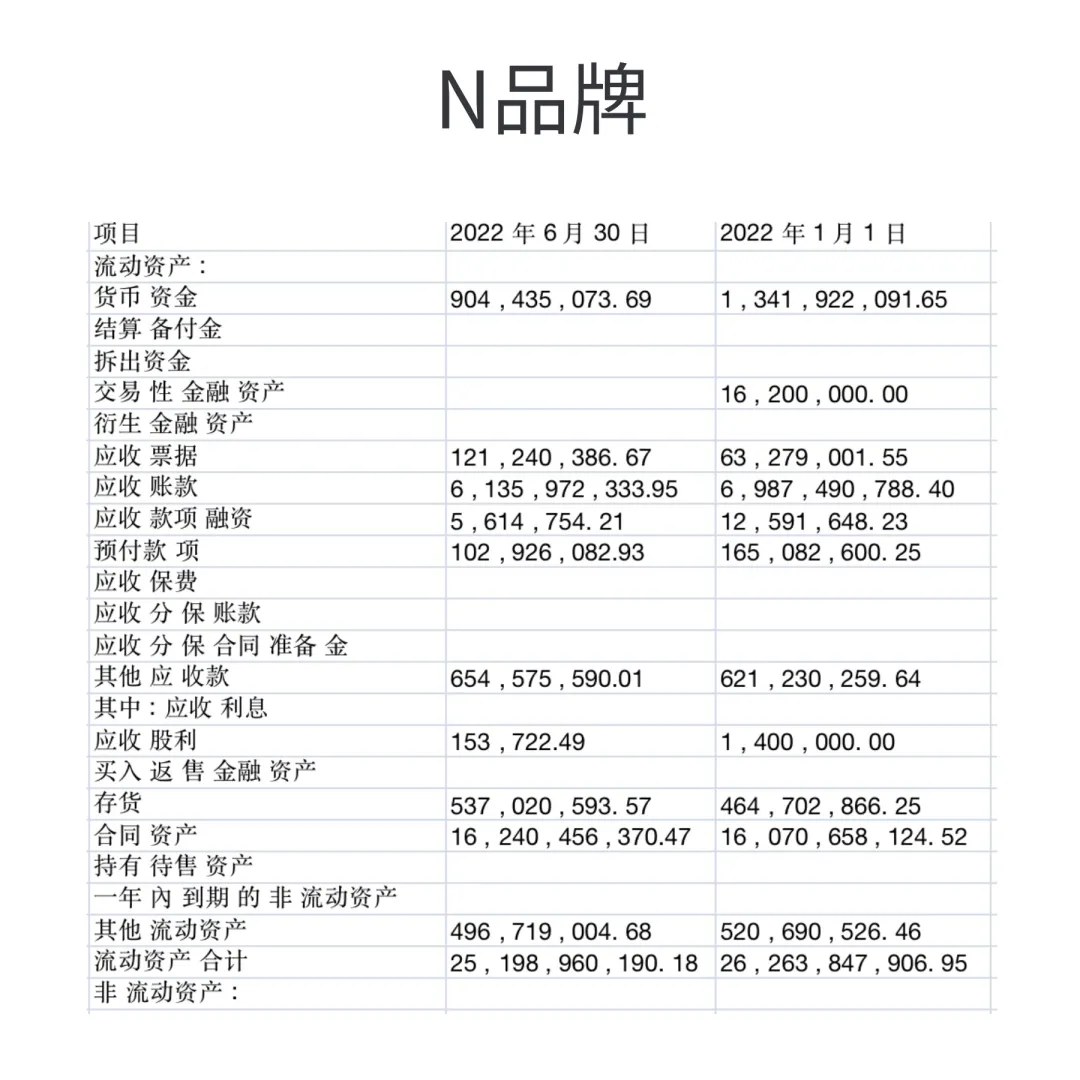

左右滑动查看处理效果
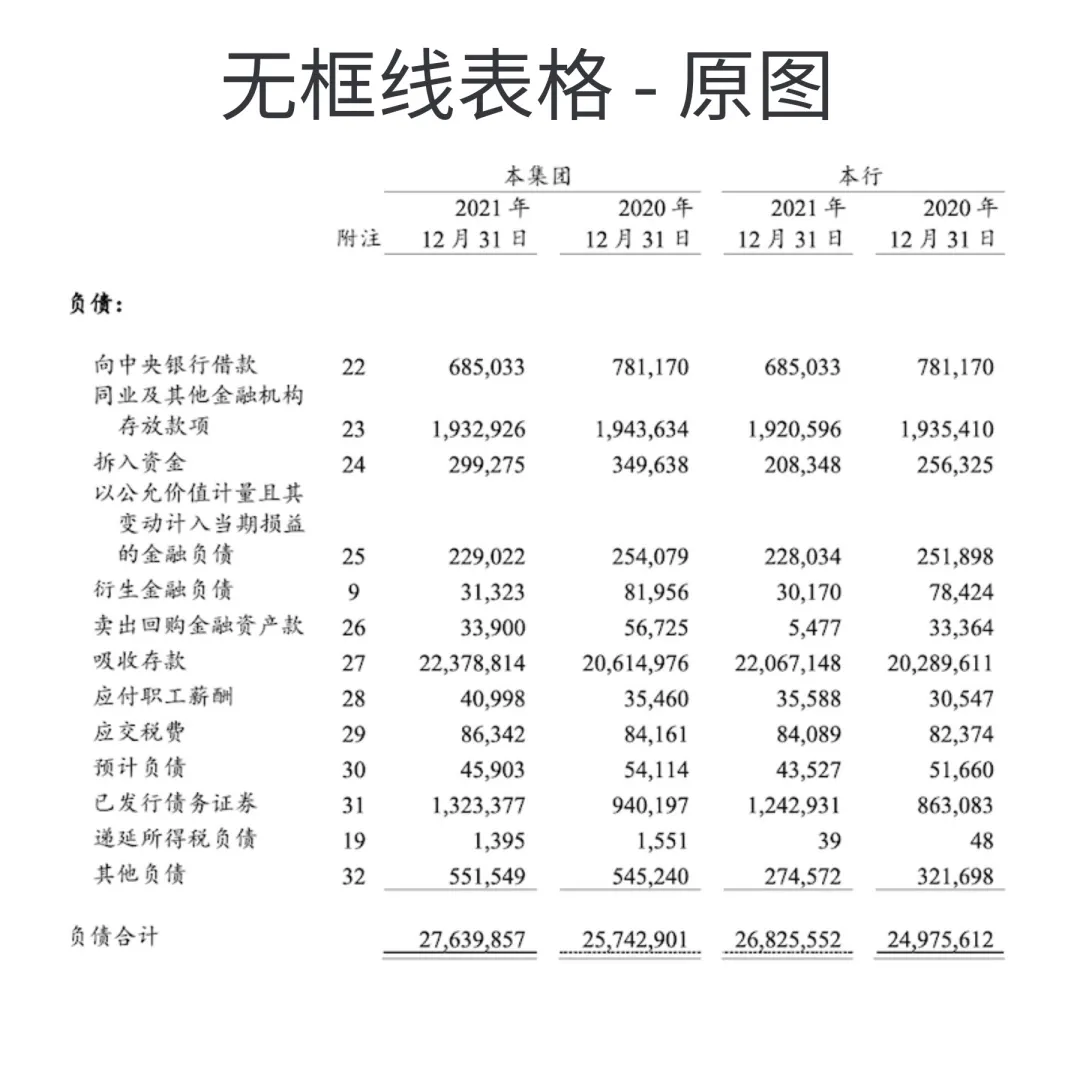

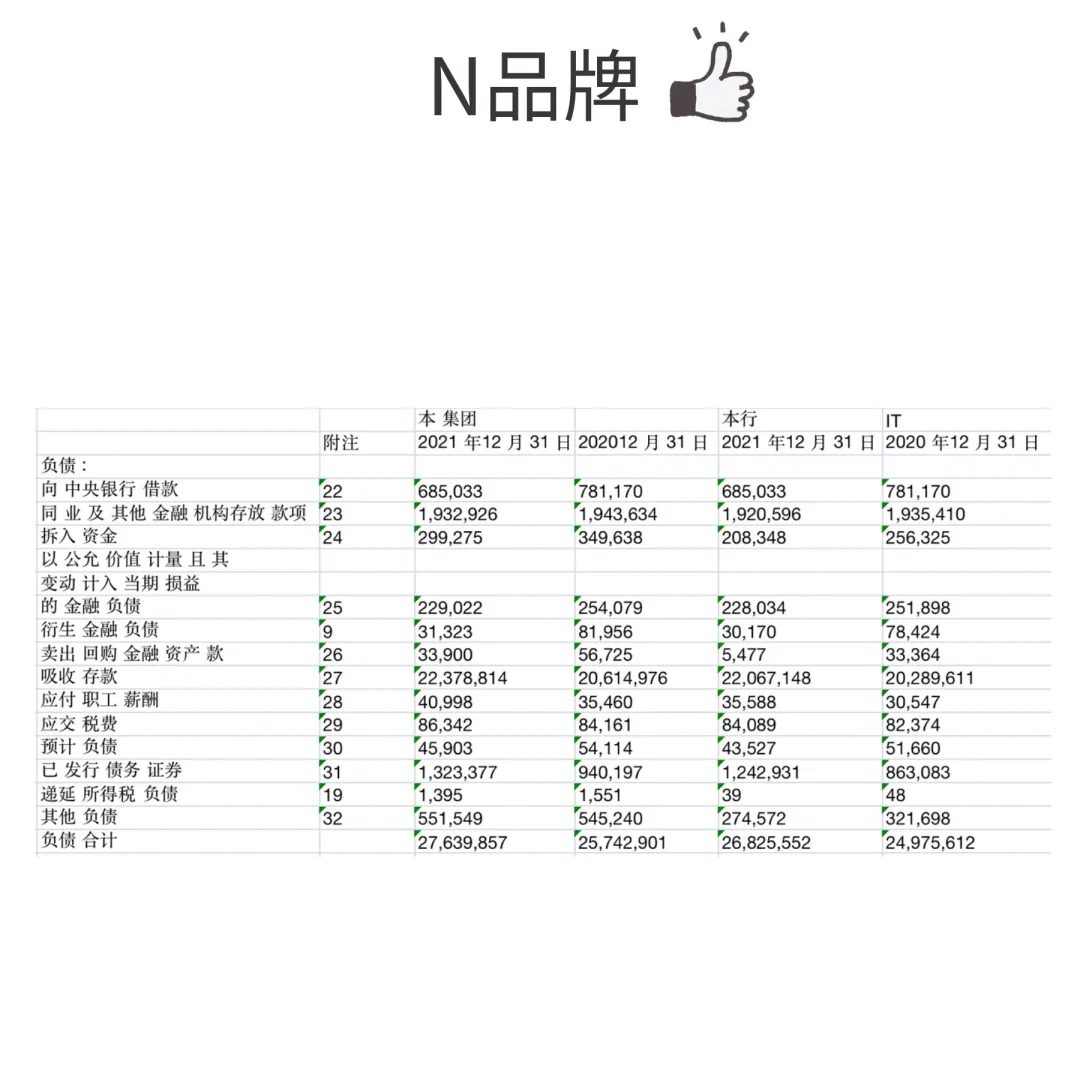
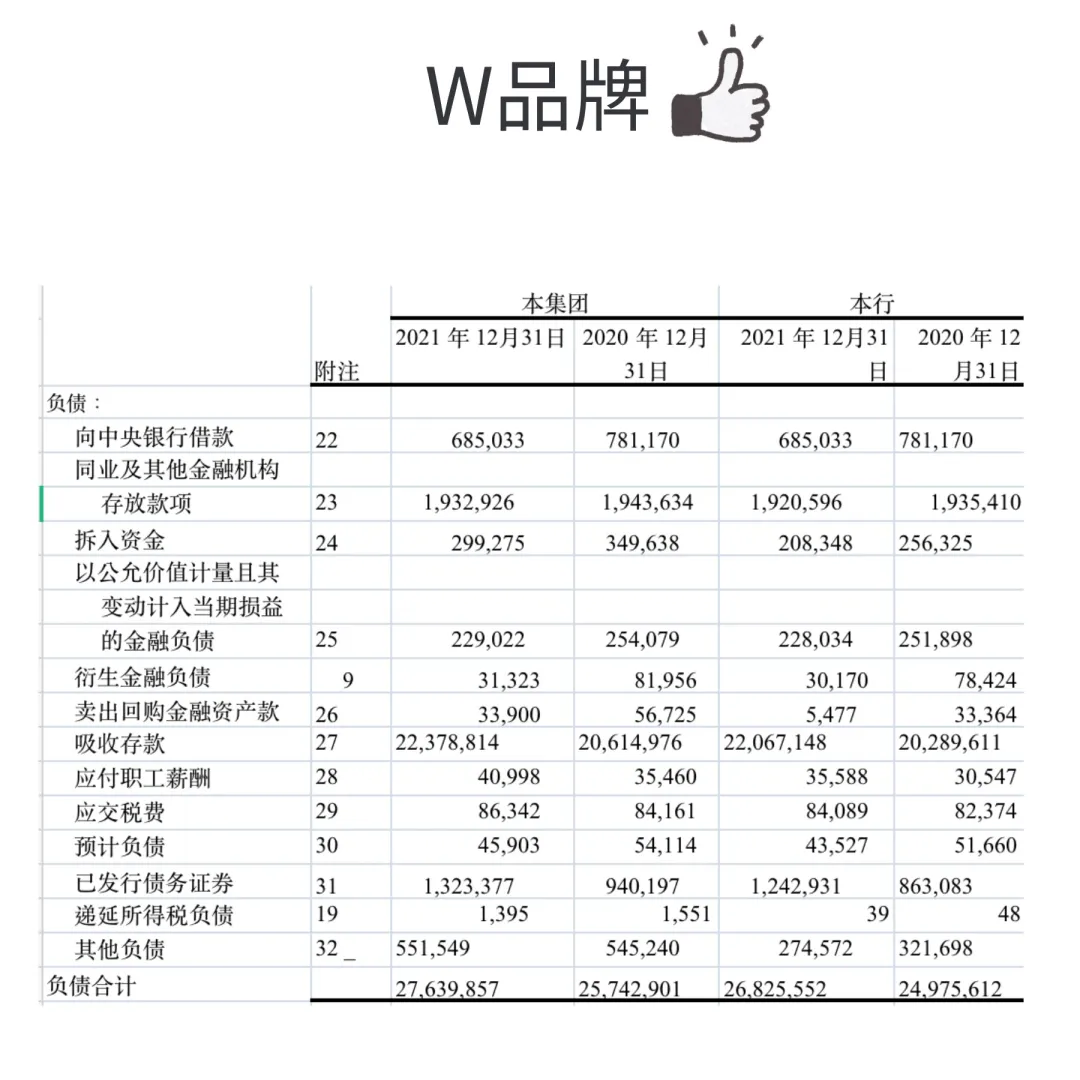

左右滑动查看处理效果





左右滑动查看处理效果
B品牌,Y品牌和W品牌:部分结构错乱
Y品牌,W品牌:出现了乱码
PDFlux,N品牌:可以较为准确识别出照片中的表格格式;但是在其中文字、数字内容的识别上,PDFlux 的准确率更高一些,达到了 90%


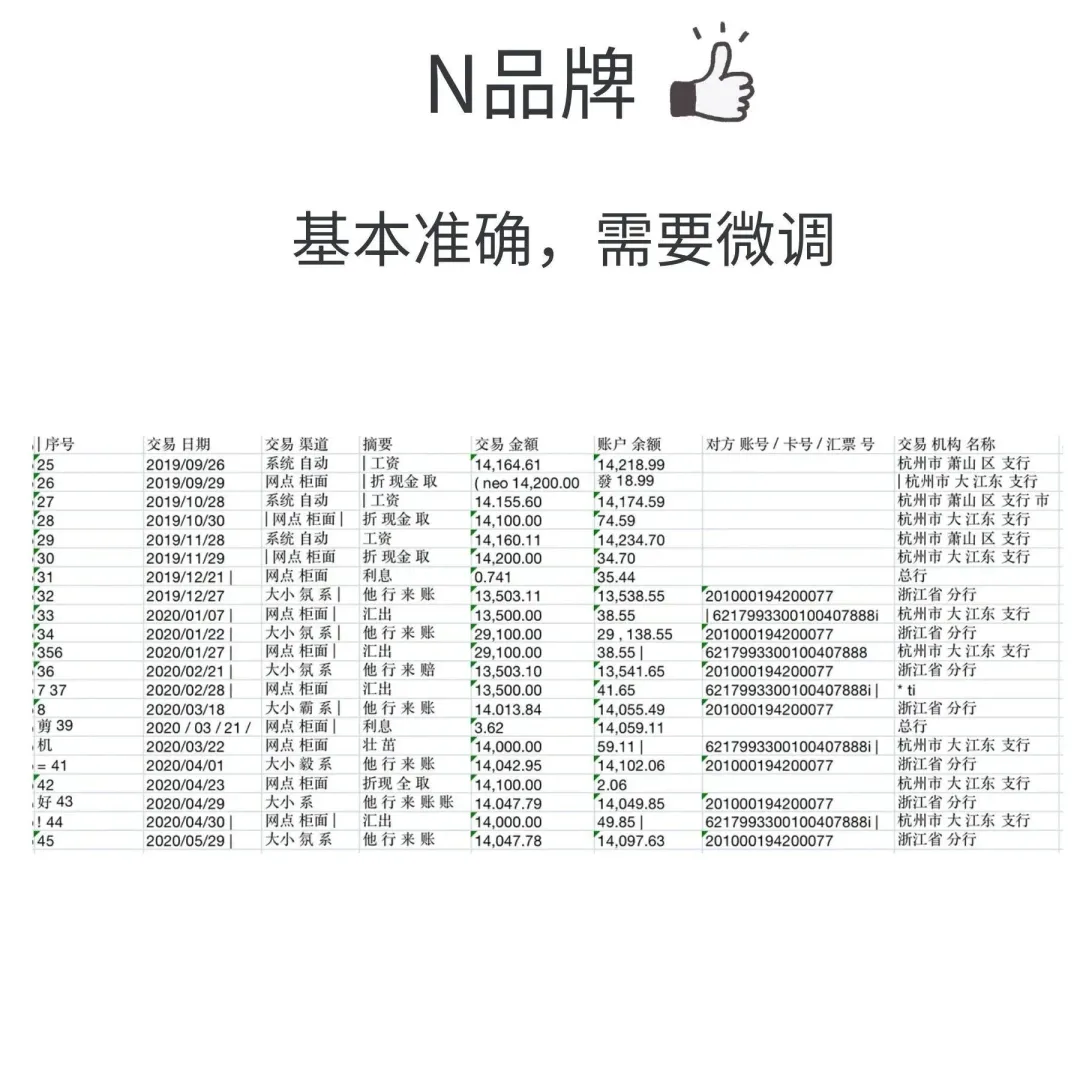



左右滑动查看处理效果
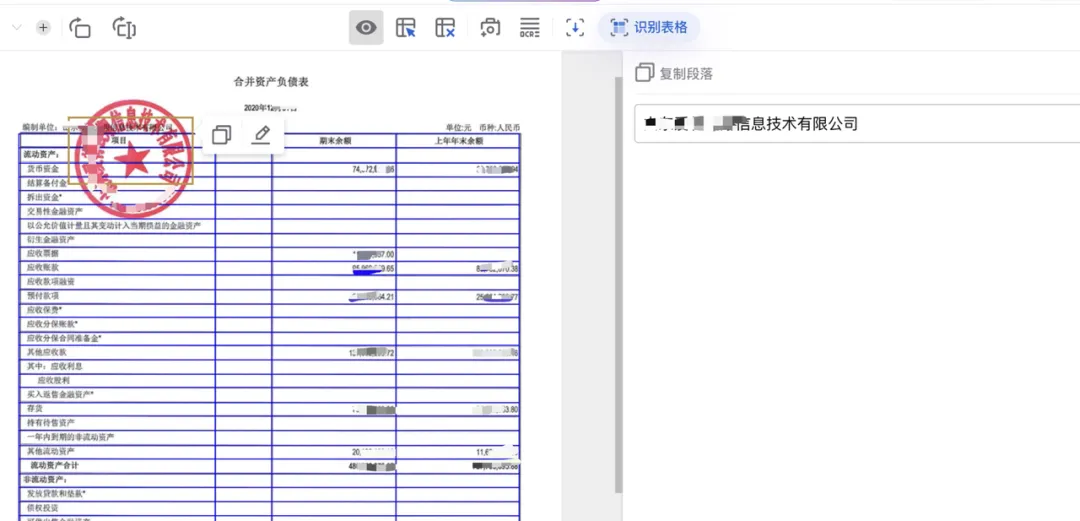
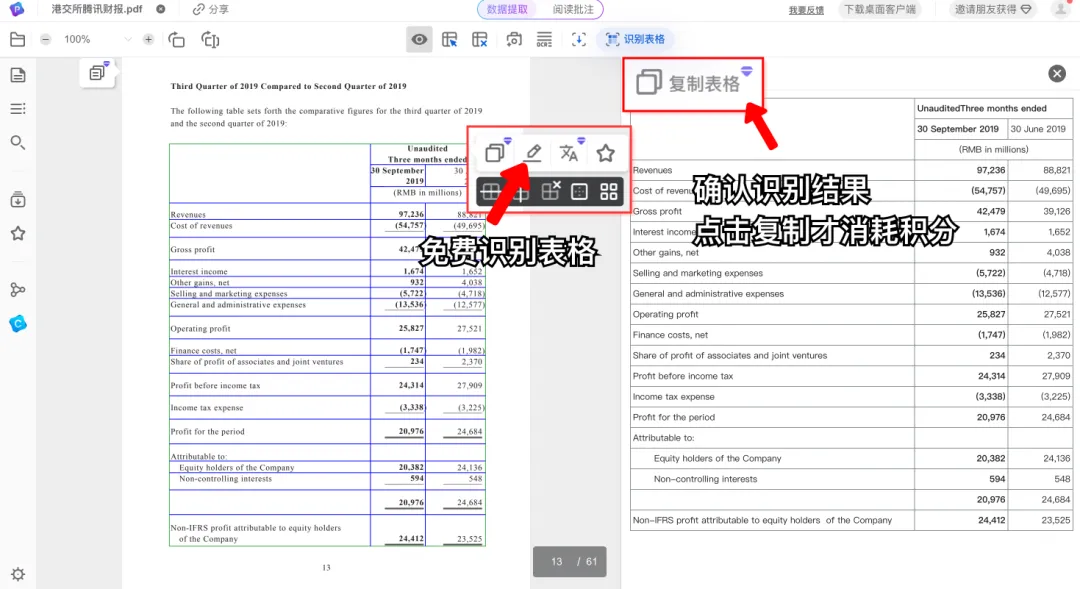
简单易用
可靠稳定
尊重用户的时间,帮用户解决问题
官网:https://paodingai.com
邮箱:contact@paodingai.com
电话:010-58426539







