

如果AI犯错无法避免,我们该如何有效复核?

大语言模型的迅速发展正在重塑各行各业的工作方式,然而其生成内容的准确性和可靠性仍然是影响技术在实际应用中有效落地的关键因素。现有的溯源功能往往存在粒度过粗或溯源不准确等局限性,难以有效验证大模型输出的可靠性。
针对这些问题,ChatDOC重磅推出"划词溯源"功能,通过细粒度的动态溯源机制,使用户能够精确定位AI生成内容的原始来源。这一创新功能显著提升了大模型在高精度要求场景中的应用价值,为用户提供了可靠的信息验证工具。
欢迎阅读本期推送,并上手体验ChatDOC的「划词溯源」功能,立即体验。
1

大模型在生成内容时可能会产生不准确或歪曲事实的问题,这已经成为业内的共识。因此,各家产品都在界面上设置了明显的警示标识,以提醒用户在使用大模型生成的内容时保持审慎。这样做的目的是为了帮助用户识别和避免可能的误导信息。

但如果问答效果无法提升,答案的准确性无法保证,那大模型还是停留在一个有趣「玩具」的阶段,很难给一些严肃的场景创造足够的价值。
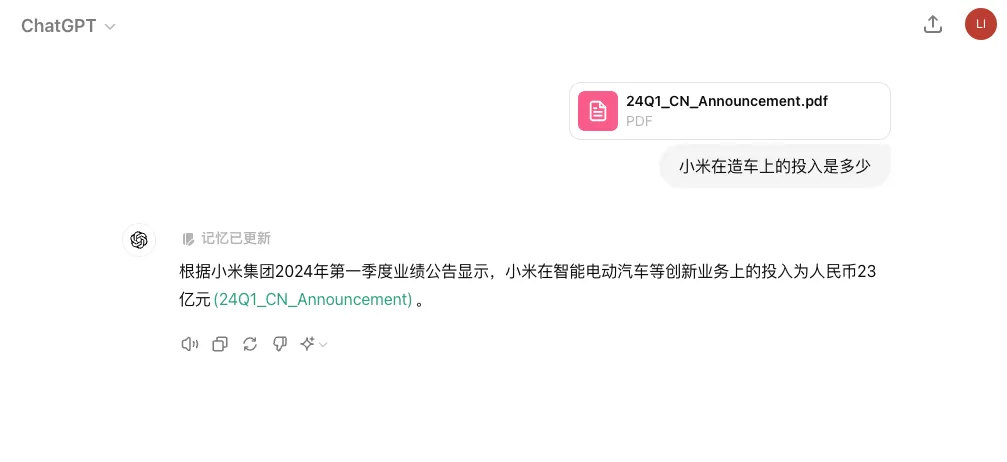
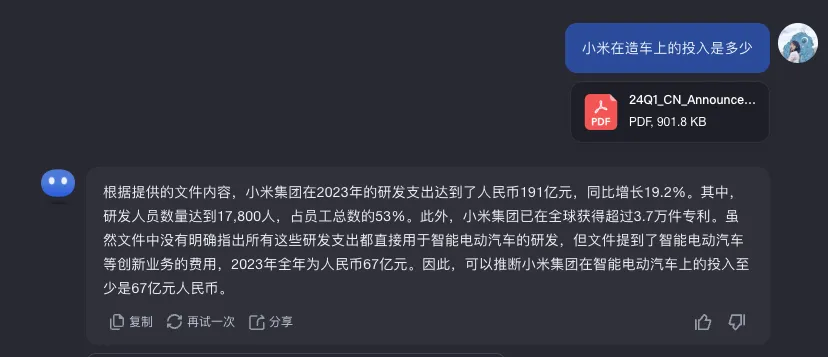
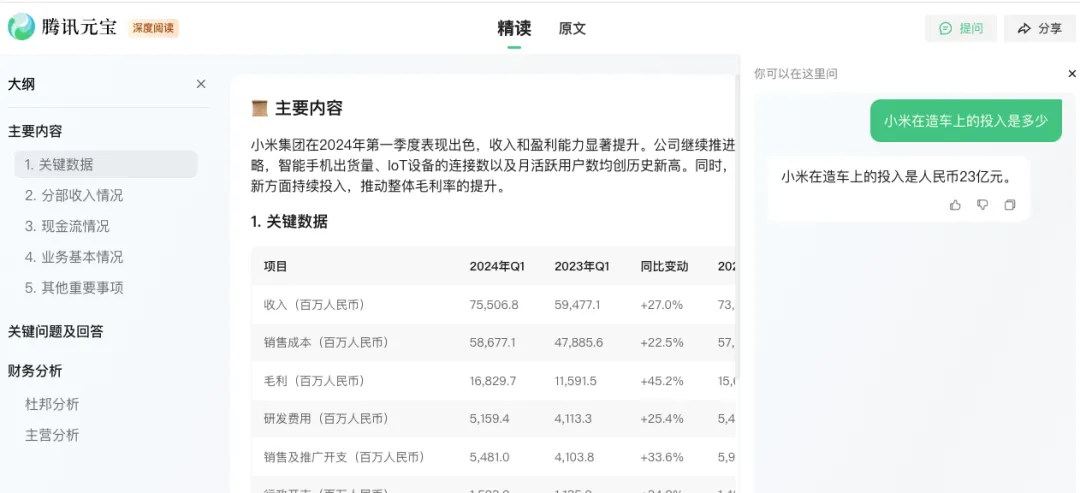
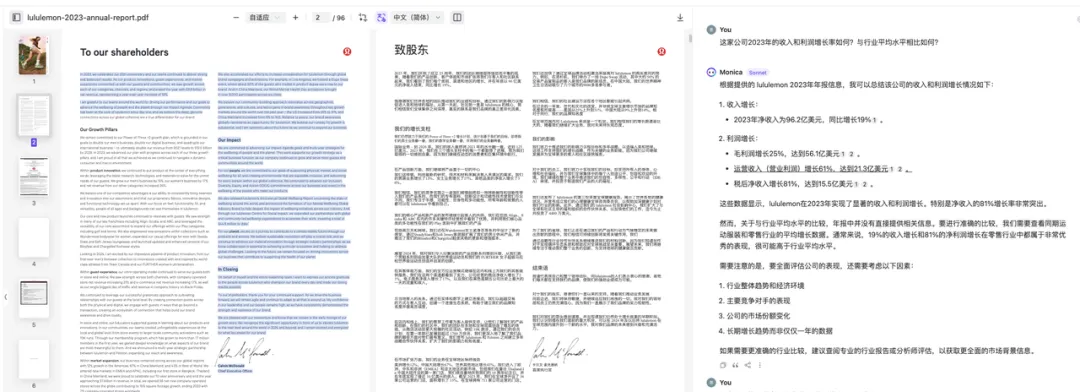
比如,当我们拿到一份小米集团 2024 年的一季报,想要了解集团在造车上的投入有多大,于是把这个问题发送给大模型,会得到各种不同的答案。

滑动了解大模型提供的回答

回到原文中,我们会发现原文中并没有明确指出小米在造车上的投入,只是提到“2024 年第一季度,小米集团總收入為人民幣 755 億元,同比增長 27.0%,經調整淨利潤為人民幣 65 億元,同比增長 100.8%,其中包括智能電動汽車等創新業務費用人民幣 23 億元。”

小米集团2024年一季报
根据原文中的这一信息,再结合大模型提供的回答,我们能够发现:
小米集团2024年一季报中并未直接说明造车方面的具体投入,而是笼统地提到包括智能电动汽车在内的创新业务费用为23亿元。面对这样的信息,不同的大模型表现出了不同的处理方式:有些直接引用了23亿元这个数字,有些仅仅复述了原文内容,还有些则基于其他相关信息给出了推测性的结论。
这个例子虽然简单,但它揭示了一个更广泛的问题:当大模型面对各种复杂的文档(包括版面复杂、内容多样的材料)以及各种各样的问题时,仅仅依靠大模型提供的答案往往难以判断其准确性和可靠性。在这种情况下,AI文档阅读类产品的溯源功能就显得尤为重要,它能够帮助用户追溯信息来源,验证答案的可靠性。
2
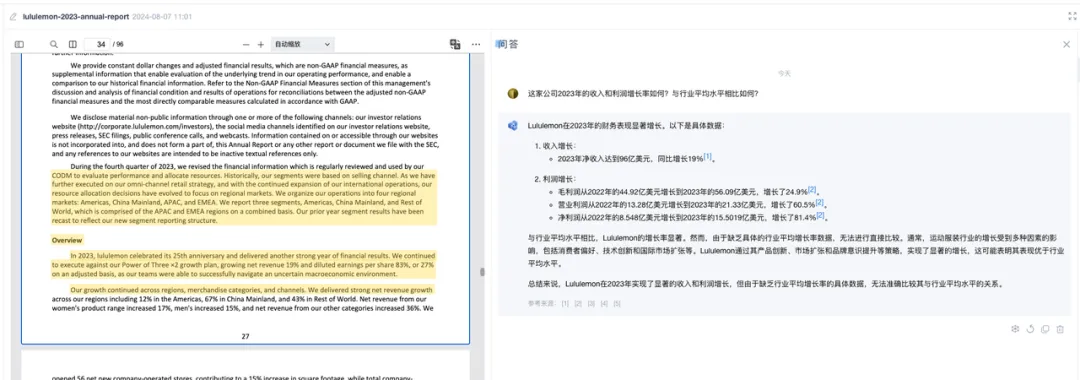
许多 AI 问答类的产品,为了减少大模型编造答案带来的不利影响,都做了列出引用来源的设计。点击页码,就能回到原文出处,在一定程度上保证 AI 回答的可靠性。
ChatDOC 一上线,我们就上了这个功能。
到后面市面上的大模型文档阅读产品越来越多,「溯源功能」也逐渐变成文档问答产品的标配。
滑动了解文档问答类产品的溯源表现
但进一步使用这些溯源功能,我们会发现以下问题:
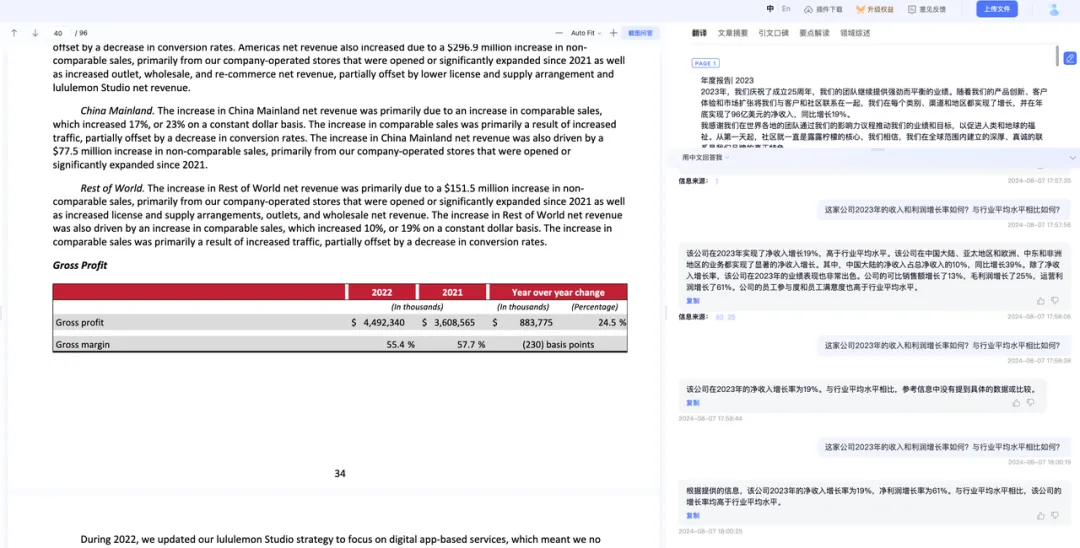
问题一:溯源提供的信息过多,提高了用户的筛选成本。
A 产品针对AI 回答内容提供了页码溯源,当我们点击相应的页码,溯源内容覆盖了该页中的大部分信息,让用户难以判定哪一部分是关键的溯源信息,提高了用户的信息筛选成本。
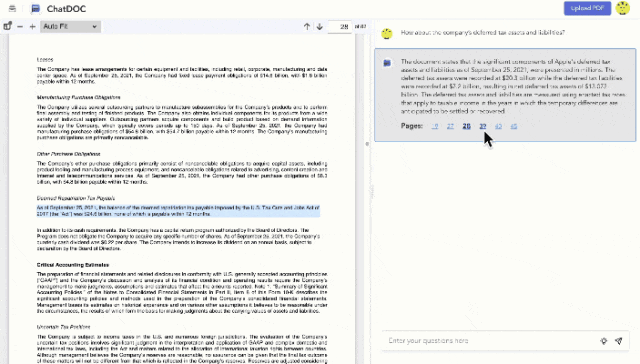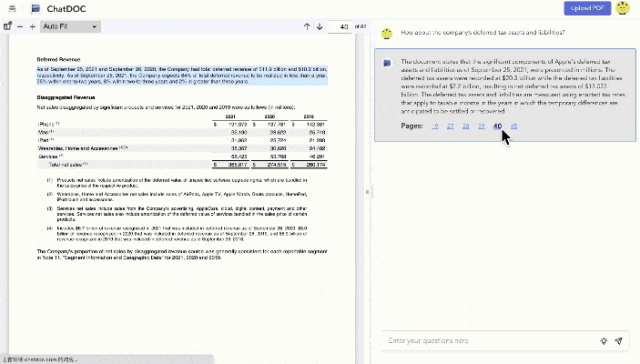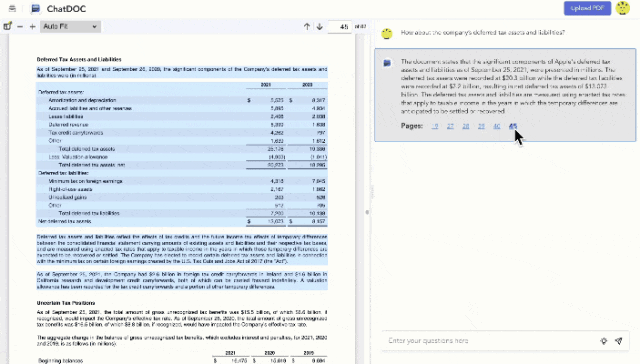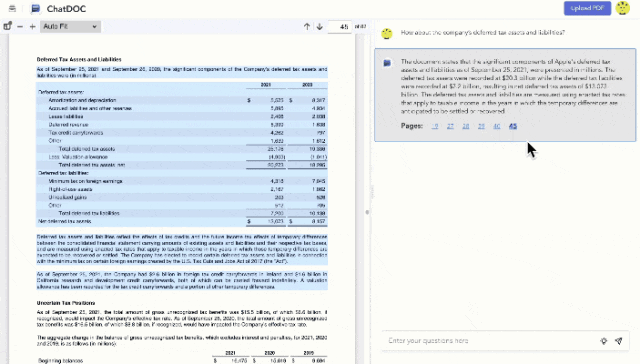
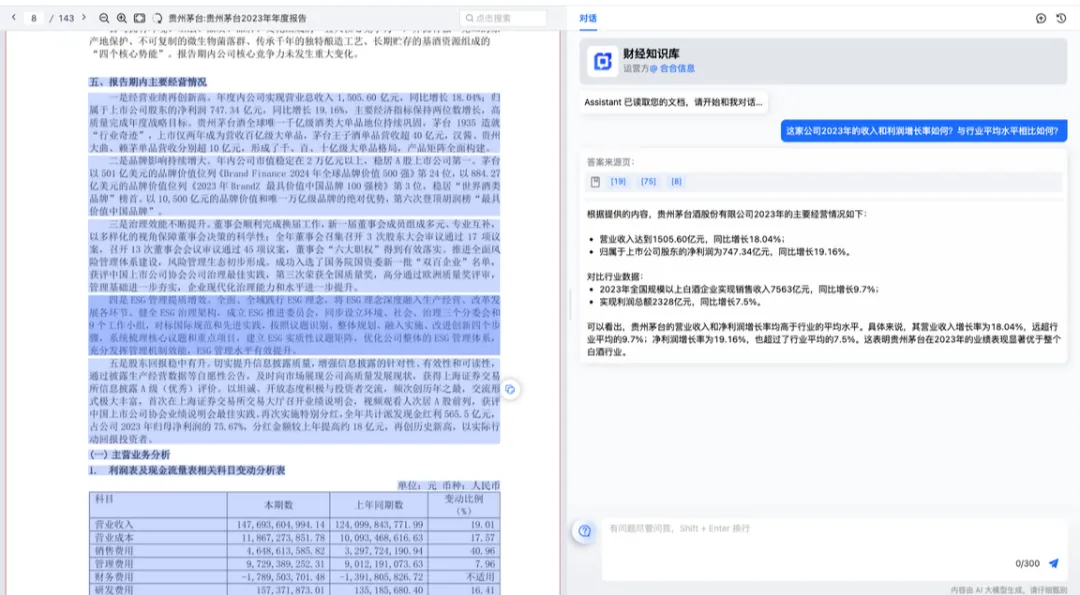
问题二:溯源提供的信息有误,存在大量的无效信息。

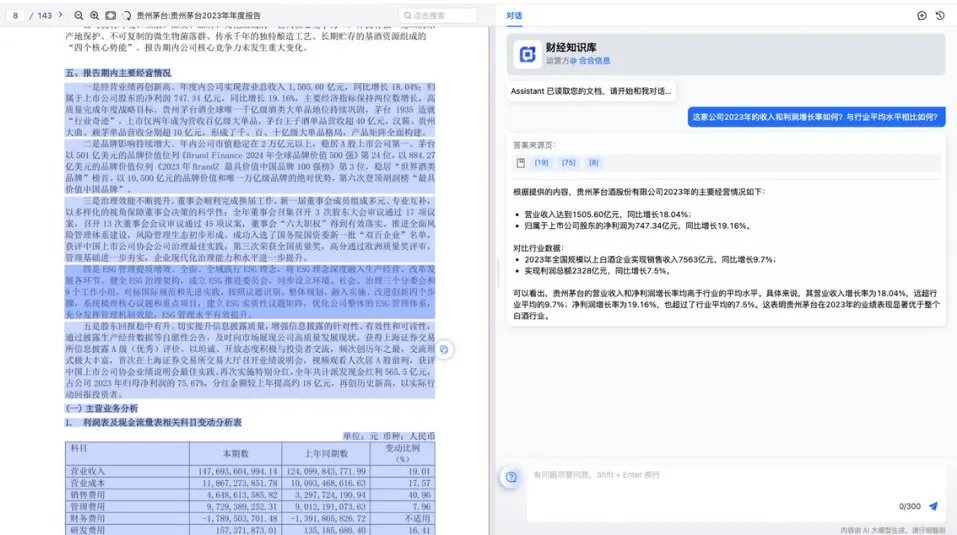
B 产品针对 AI 回答内容提供数据关键点溯源,但部分回答内容所对应的溯源信息有误。例如在图示中C产品指出“2023年的毛利率为58.3%”,并溯源指向左侧原文信息,但溯源选中文段中并没有说明这一数据。
问题三:问答溯源信息不充分,只对部分回答提供溯源。
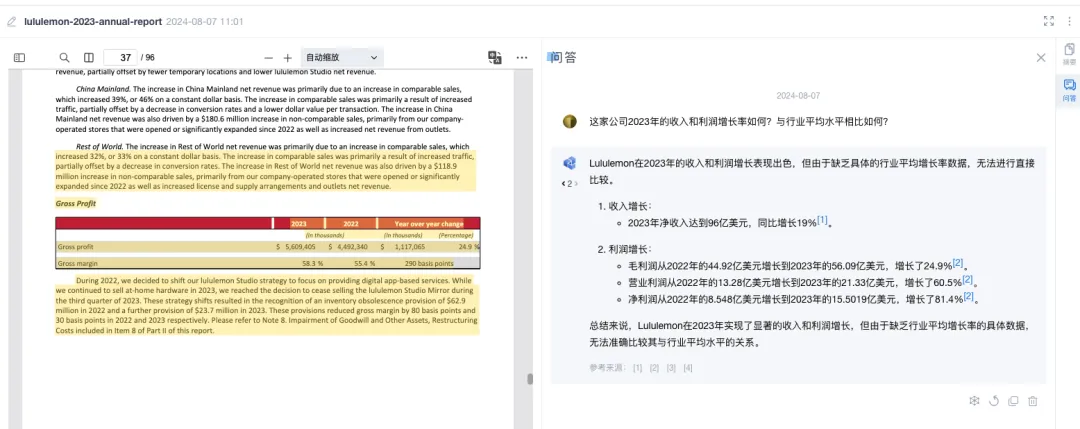
C产品针对 AI 回答内容提供了页码溯源和数据关键点溯源,但没有针对“净利润从2022年的8.548亿美元增长到2023年的15.5019亿美元,增长了81.4%”这一回答提供对应的原文信息,和前面的回答内容一起溯源到无关文档片段中。
综上,溯源似乎成为了一种表面工作,看似提供溯源,但事实上并没有帮用户找到对应的内容。
3
本着要大模型具备解决真实场景问题的初心,我们在这个方向上又往前探索了一步:实现文档问答内容的细颗粒度动态溯源,哪里不确定划哪里。
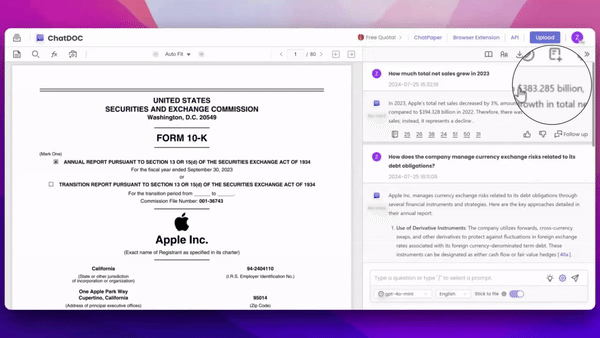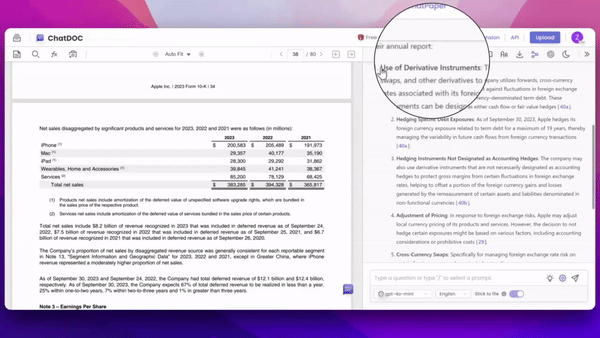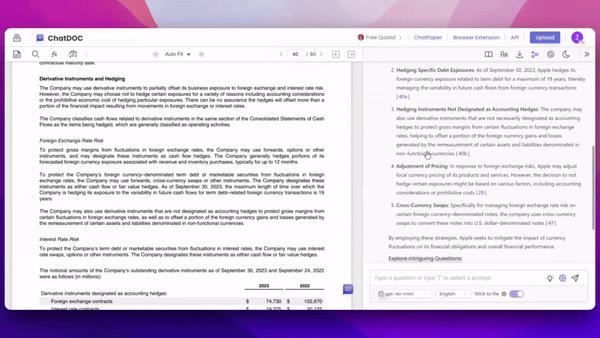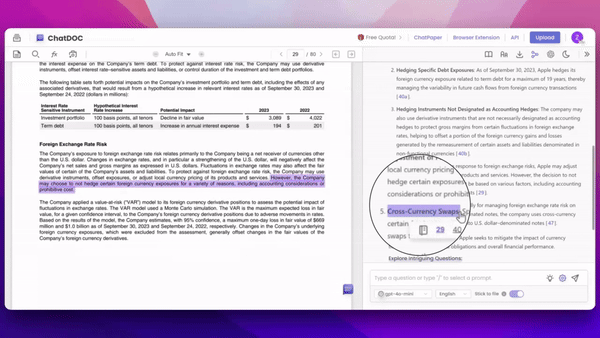
用户上传文档到ChatDOC中进行提问并得到回答后,如果对回答内容有疑问,只需用鼠标“划选答案中的文本”,文档便会跳转至"相应信息"的引用出处,并且,我们尽可能地溯源到关键信息当中,减少信息冗余。
🧙功能亮点:
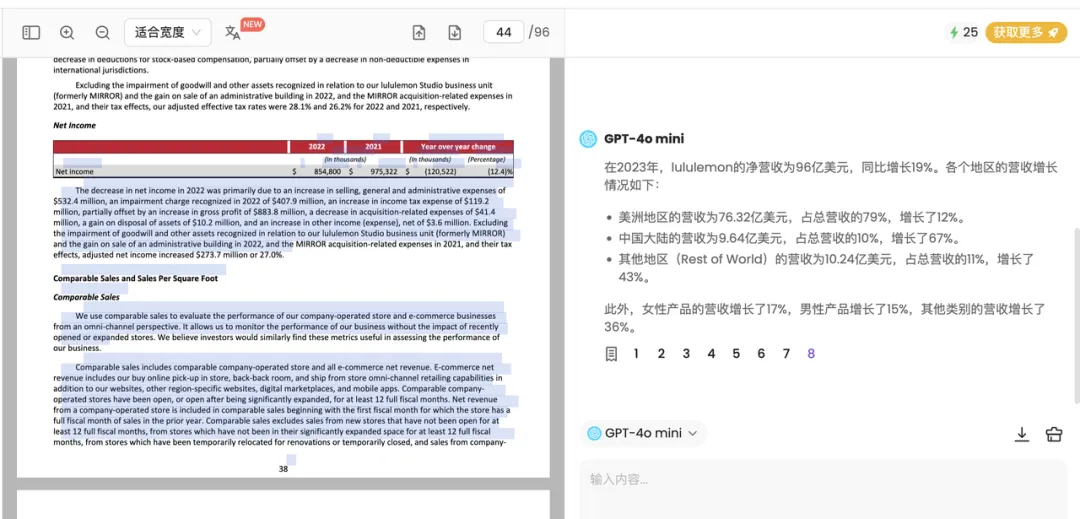
1. 主动溯源:用户可对AI回答中的任何部分进行选择,系统会自动验证所选内容的真实性,实现精确定位和验证。
2. 细粒度溯源:ChatDOC能够精准定位到原文中最相关的关键信息,避免提供冗长或不必要的内容,确保溯源结果简洁有效。
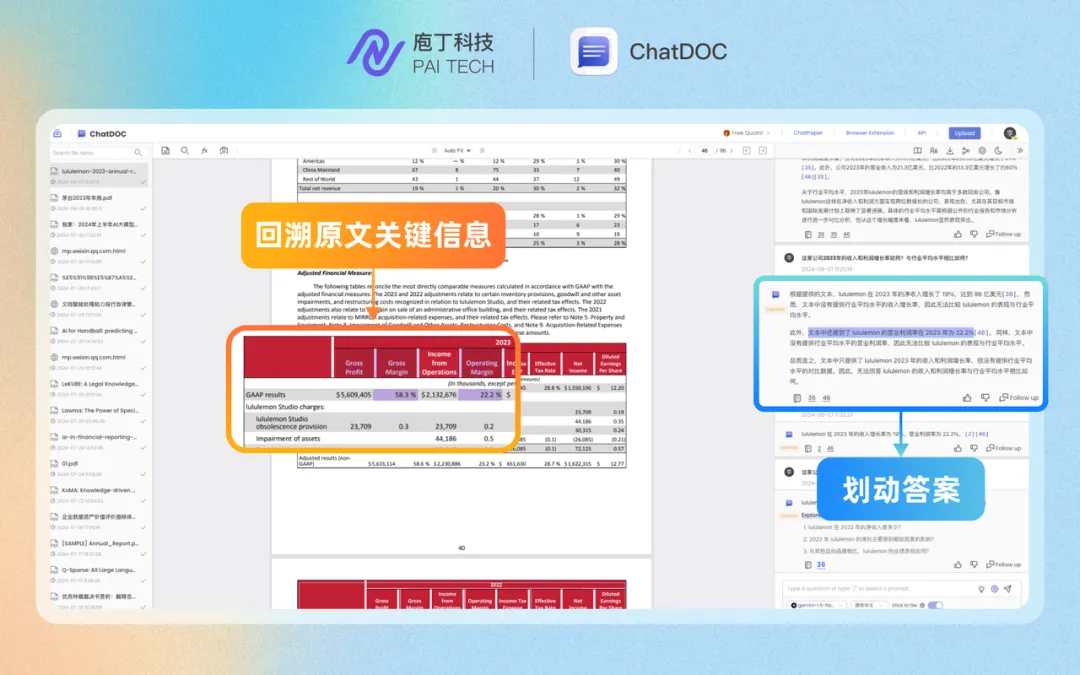
在图示中,当用户划中“lululemon 的营业利润率在 2023 年为 22.2%”这一回答内容,ChatDOC自动溯源到原文表格中的对应信息,高亮展示22.2%这个关键数据,帮助用户更快更准确的核验内容。
4
借助「划词溯源」这个功能,在一些专业、严谨,对内容容错率低的应用场景中,大模型应用的效果将得到显著的提升。
例如庖丁科技的朋友们经常会提到「招股书底稿溯源审核」这个场景需求,招股书中的内容来自于大量的项目底稿,质控人员要审核招股书上的内容和关联底稿之间的一致性。当用上“划词溯源”功能,底稿审核的效率也会大幅提升。
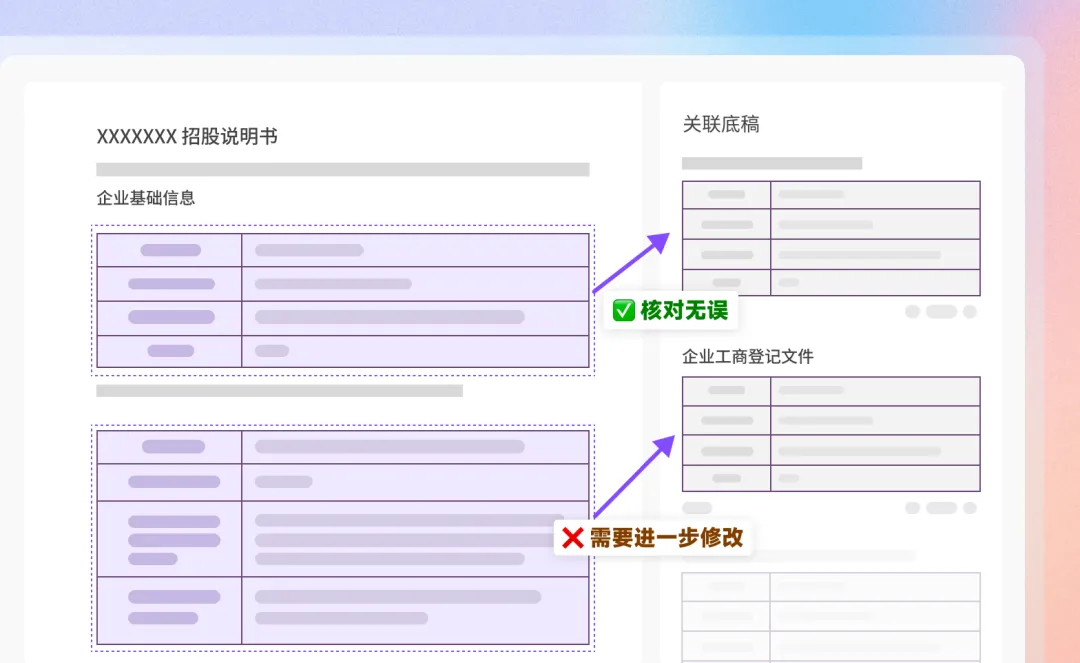
当然,还有其他一系列类似的场景,之后我们也会逐一介绍,敬请期待:)
大模型的出现给我们的工作方式带来了极大的改变,我们每个人在积极拥抱这一「新质生产力」时,也时刻用专业审慎的态度对待 AI 生成的内容,毕竟我们都知道 AI 没办法给我们背锅,用户要为 AI 生成的内容承担不利后果。在这种背景下,ChatDOC的"划词溯源"功能应运而生,旨在帮助用户更好地验证和追溯AI生成的信息,从而提高使用AI的可靠性。
5
欢迎体验 ChatDOC 的「划词溯源」功能,哪里不确定划哪里。
立即体验:立即体验🪄







