

PDF 内容提取:像 Word 一样丝滑流畅
PDF格式诞生于1992年,它能够在任何计算机系统中保证完全一致的视觉展示效果,因此被业界广泛使用。然而,PDF文档中的内容提取一直是困扰业界几十年的技术难题。例如,在 Adobe、WPS、福昕等知名公司提供的 PDF 阅读器中,选择段落或句子等看似简单的内容提取操作,远远不如在 Word 文档中那么丝滑流畅。
本文将介绍庖丁科技研发的 PDFlux 阅读器如何让 PDF 内容提取像 Word 文档一样简单方便。同时,这一功能已开放给大家使用。
01
PDF vs Word 内容提取,
差距在哪里?
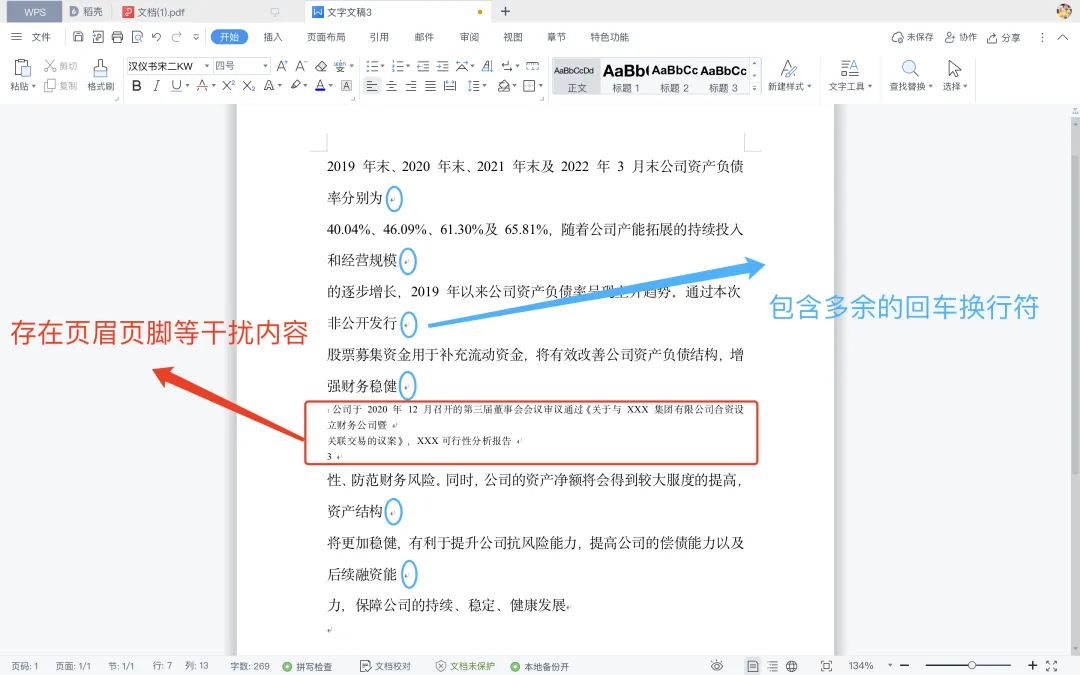
在 Word 编辑时,如果我们想选取整段内容,只需要用鼠标左键三击,选中文字后可方便的进行复制粘贴等基础操作,如下图所示:

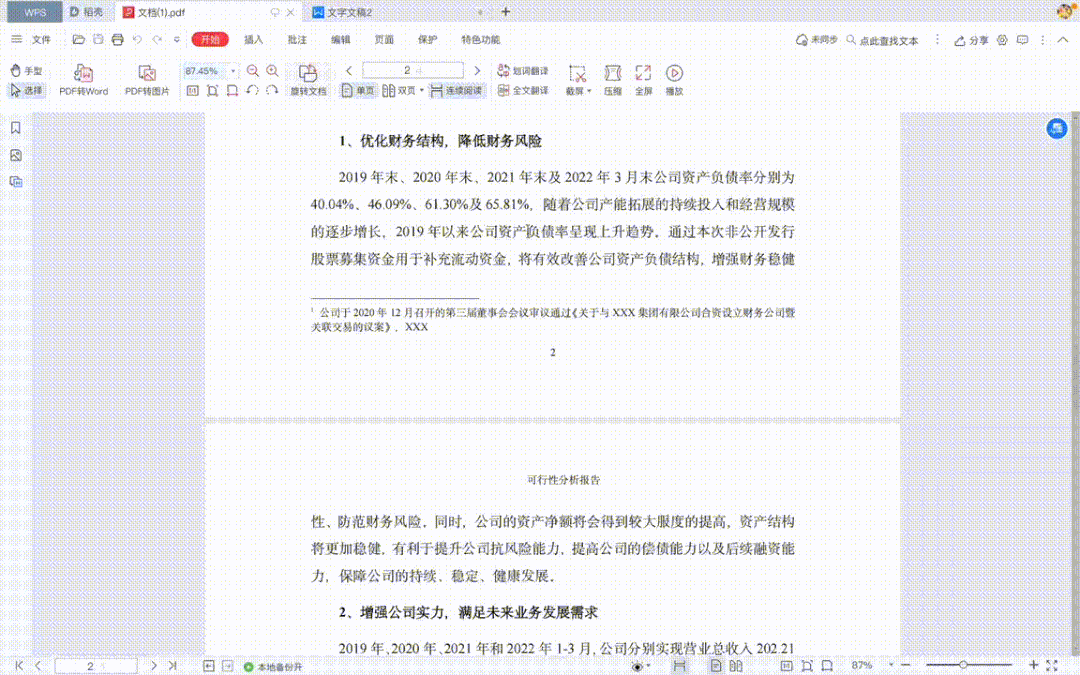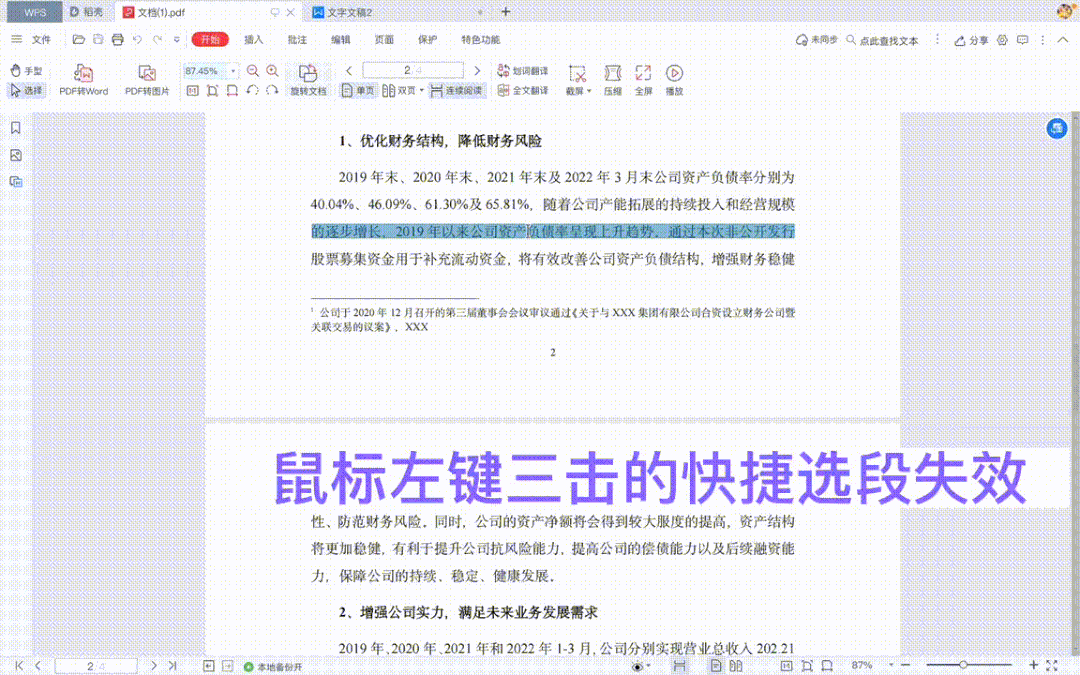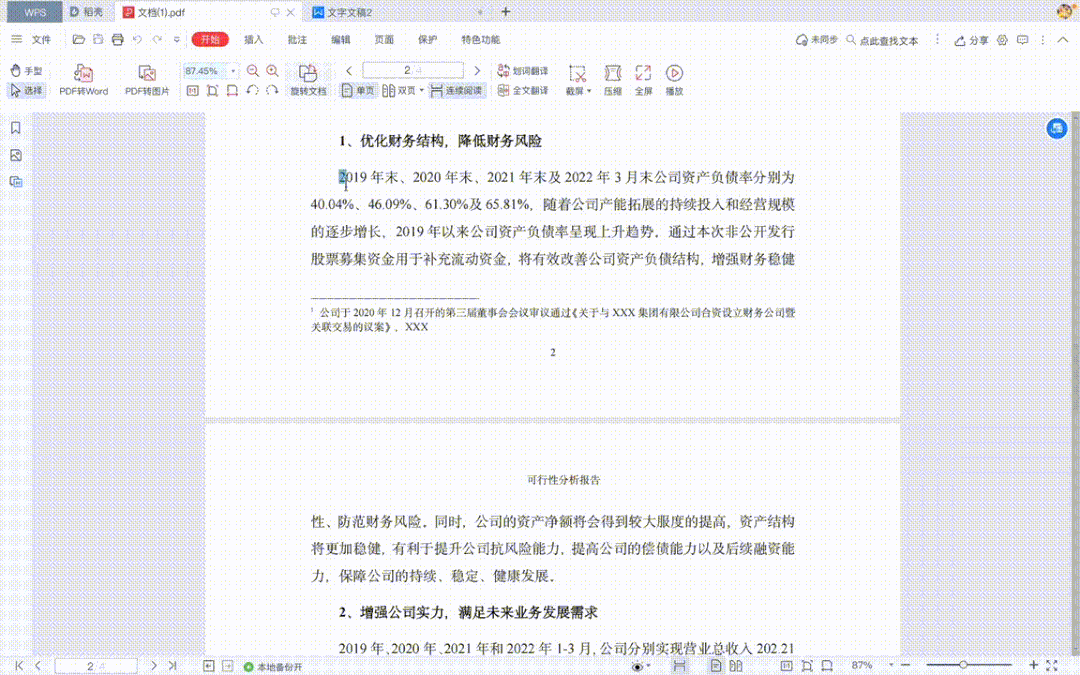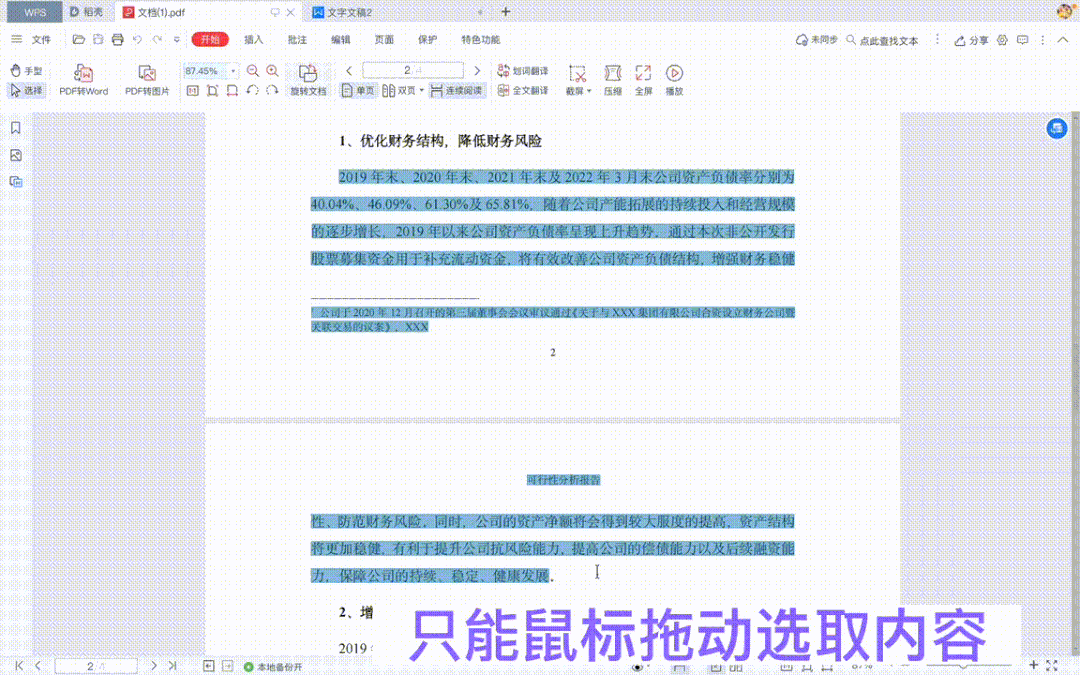
然而,在 PDF 中,同样的内容提取就显得异常困难,如图所示:鼠标左键三击的快捷选段失效,只能通过鼠标拖动选取内容:
同时,复制粘贴后的内容除了包含不必要的页脚内容外,还多余了很多回车换行符号,为后续的编辑带来很多麻烦:
这并不是特例,是所有 PDF 阅读器中的普遍现象。
02
PDF 内容提取,
难在哪里?
这就得从 PDF 的设计初衷谈起。为了忠实再现原稿的每一个字符、线条、图像等内容,PDF 文档储存的是一条条绘制视觉基本元素(包括字符、线条、色块、图片等)的程序指令。
换句话说,PDF 就是电子版“活字印刷术”,只是简单的把字符“印刷”上去了,却根本无法识别这些字符所构成的句、段落、章节等文档结构信息。更多关于 PDF 文档格式的介绍请参见我们的往期文章《电子文档全景结构识别漫谈》。
因此,常见的 PDF 阅读器只能根据字符在页面中的位置和存储顺序来获取所选择文字内容,而无法自动框定鼠标所在位置所处的段落区域;进而产生了如前所述的不便之处。
为了在 PDF 文档中提供如 Word 文档一样的丝滑便捷的内容选取功能,我们必须模拟人脑的认知过程,让计算机“读”懂 PDF。从技术的角度说,这个过程叫做文档全景结构识别,即:
文档全景结构识别(Panoptic Document Structure Recognition):对所输入的多页且复杂排版的电子文档,生成一个丰富而完整的文档的物理结构和逻辑结构。
具体步骤可分解为:物理对象检测、跨页(栏)对象合并、阅读顺序调整、文档逻辑结构识别等模块。

因此,看似简单的内容提取的功能,却蕴含着大量底层 AI 模型的支撑。
03
PDF 内容提取,
PDFlux 轻松搞定!
庖丁科技自主研发的 PDFlux 经过不断的训练和迭代,已支持快捷键智能选中词语、句子和段落,支持自动识别和合并跨行、跨栏、跨页的内容,支持对选中内容一键复制和翻译,让 PDF 内容提取也能像使用Word 一样丝滑顺畅,简单方便!
仅需打开 PDFlux ,选择「阅读批注」模式,就可以免费体验啦~
体验网址:https://pdflux.com
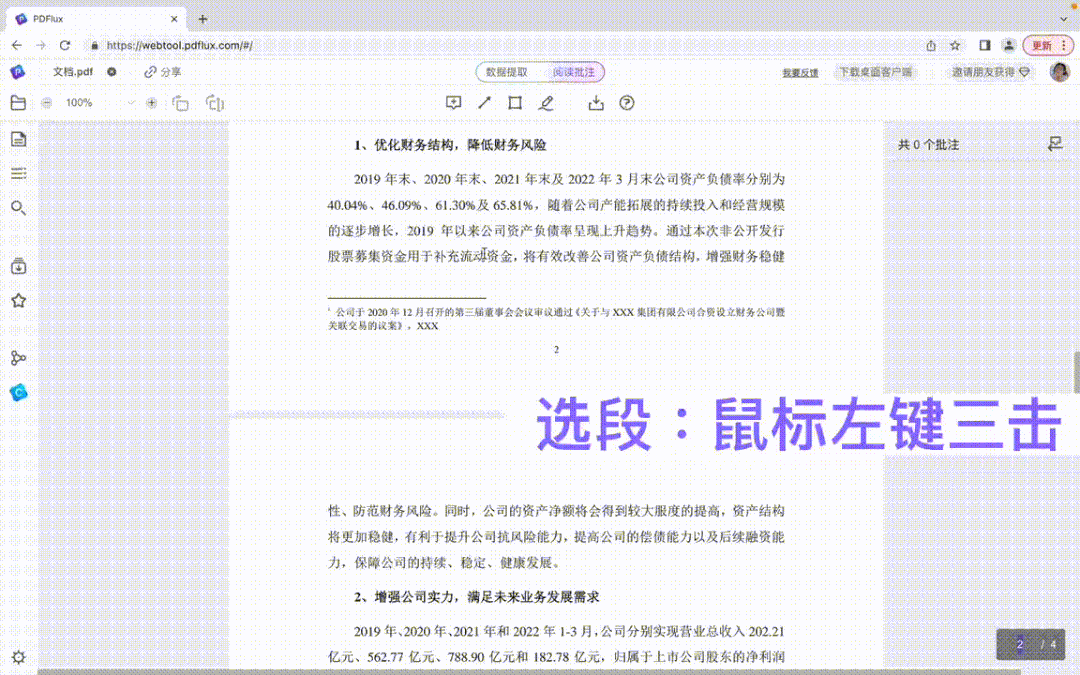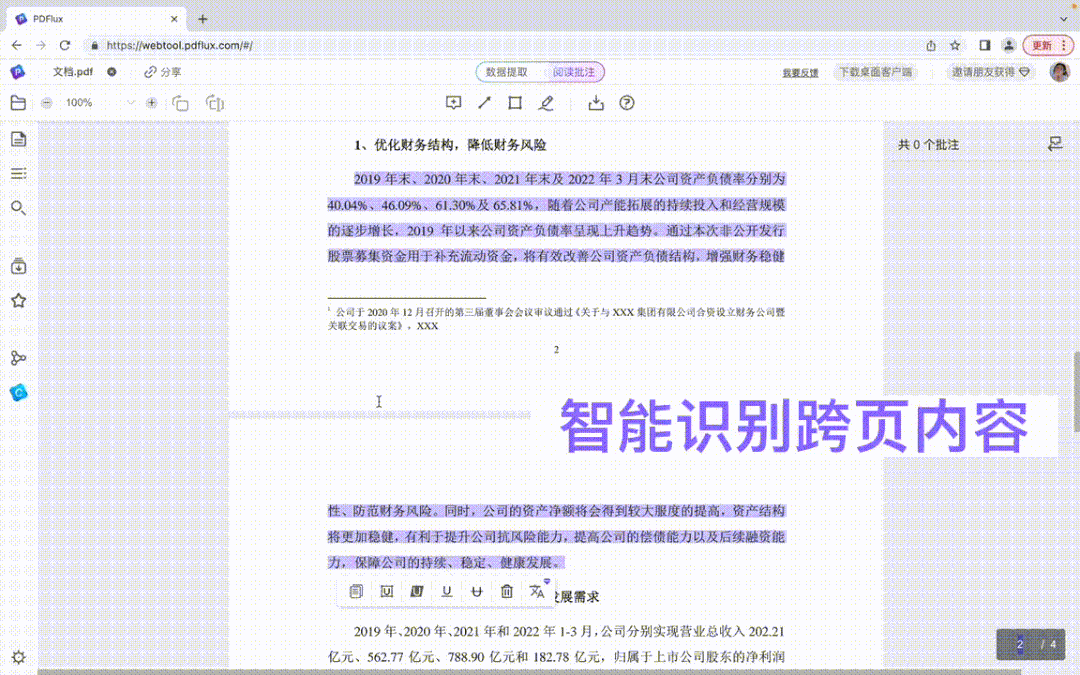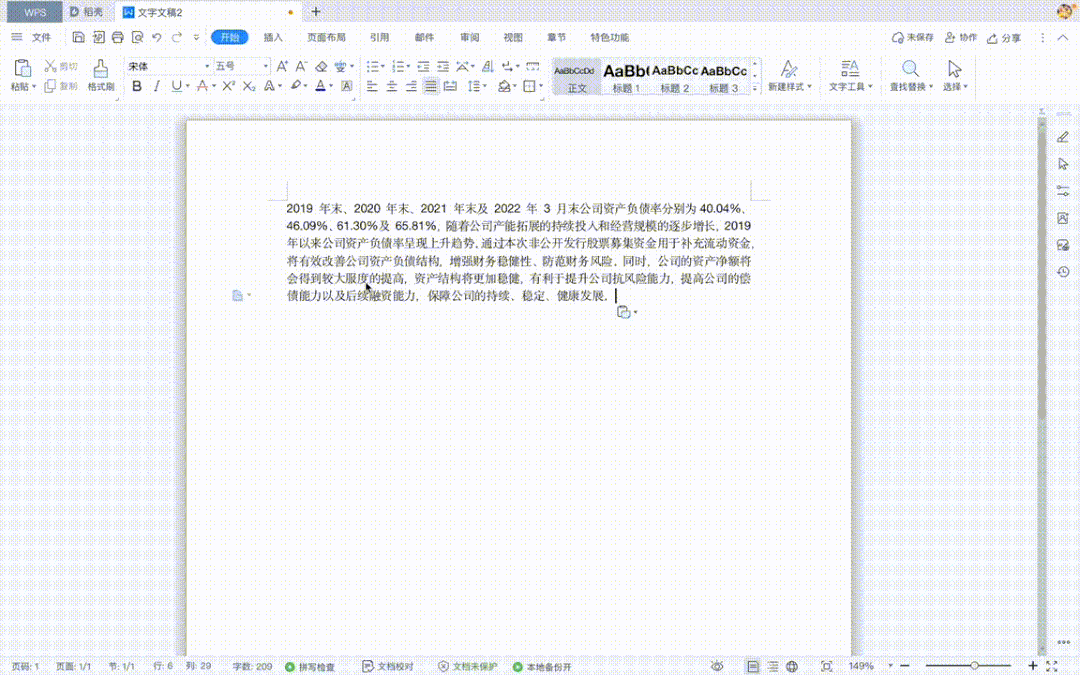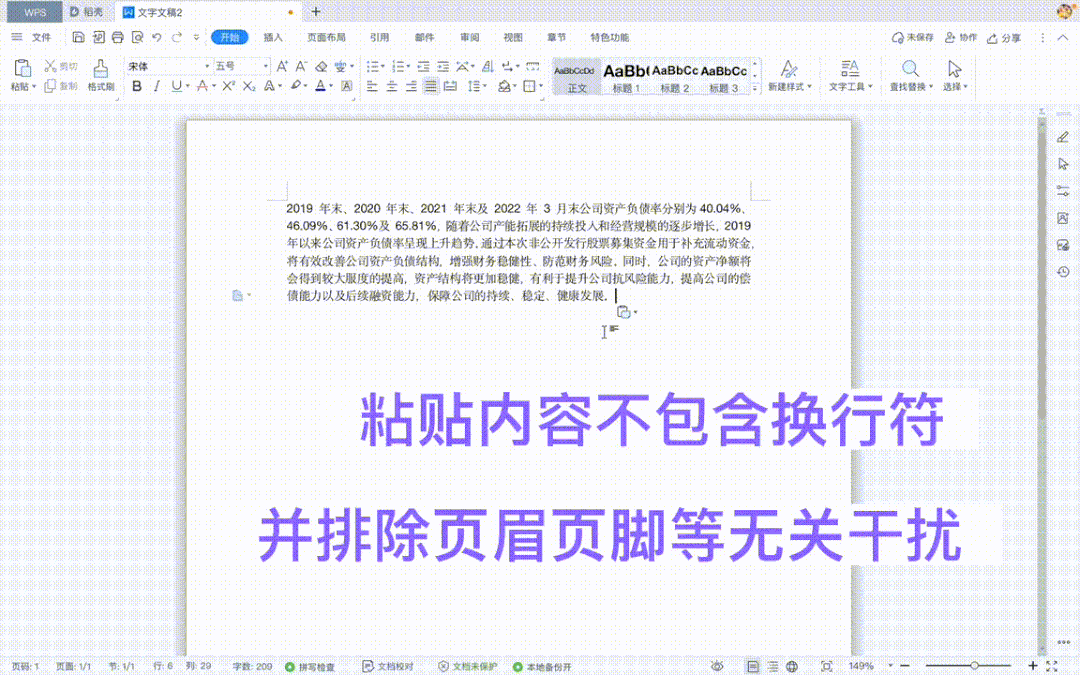
#选段:鼠标左键三击#

#选句:Alt/Option+鼠标左键单击#

#选段翻译:Ctrl + 鼠标左键三击#

#选句翻译:Ctrl+ Alt/Option+鼠标左键单击#

#选词翻译:Ctrl + 鼠标左键双击#
04
联系我们
PDFlux 作为庖丁科技自主研发的 PDF 文档智能分析产品,除了可以智能识别和提取 PDF 中的文字之外,还可以提取其中的表格信息及其他元素,并一键复制到 Word、Excel、PPT 中。







